用户:nowhere
2023-12-27 22:34:49 晴
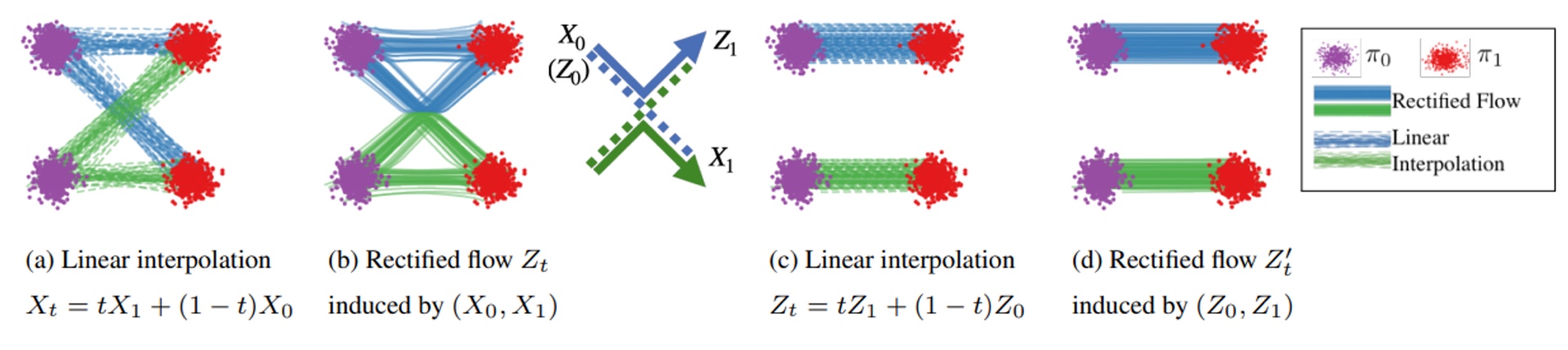
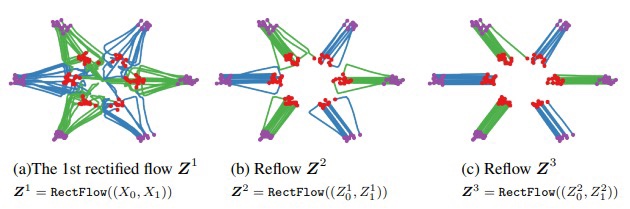
由neural ode的性质,prior distribution和image distribution是bijective mapping,所以probability path的交叉区域可以被模型自动分开。以此为动机,对生成模型预测的data pairs进行迭代的rectified flow,可以得到更加笔直的probability path,从而实现单步生成。但是反复迭代rectified flow又会累加生成图像误差。所以需要权衡模型推断时的采样步数和生成图像质量。
#学习#学习 #phd#PhD日常 #ai#AI >>阅读更多
用户:鼎天犁地
2024-04-17 19:17:34 晴
#孤独并不是可怕的事 比孤独更可怕的是?? >>阅读更多

用户:nowhere
2023-11-28 23:45:48 晴
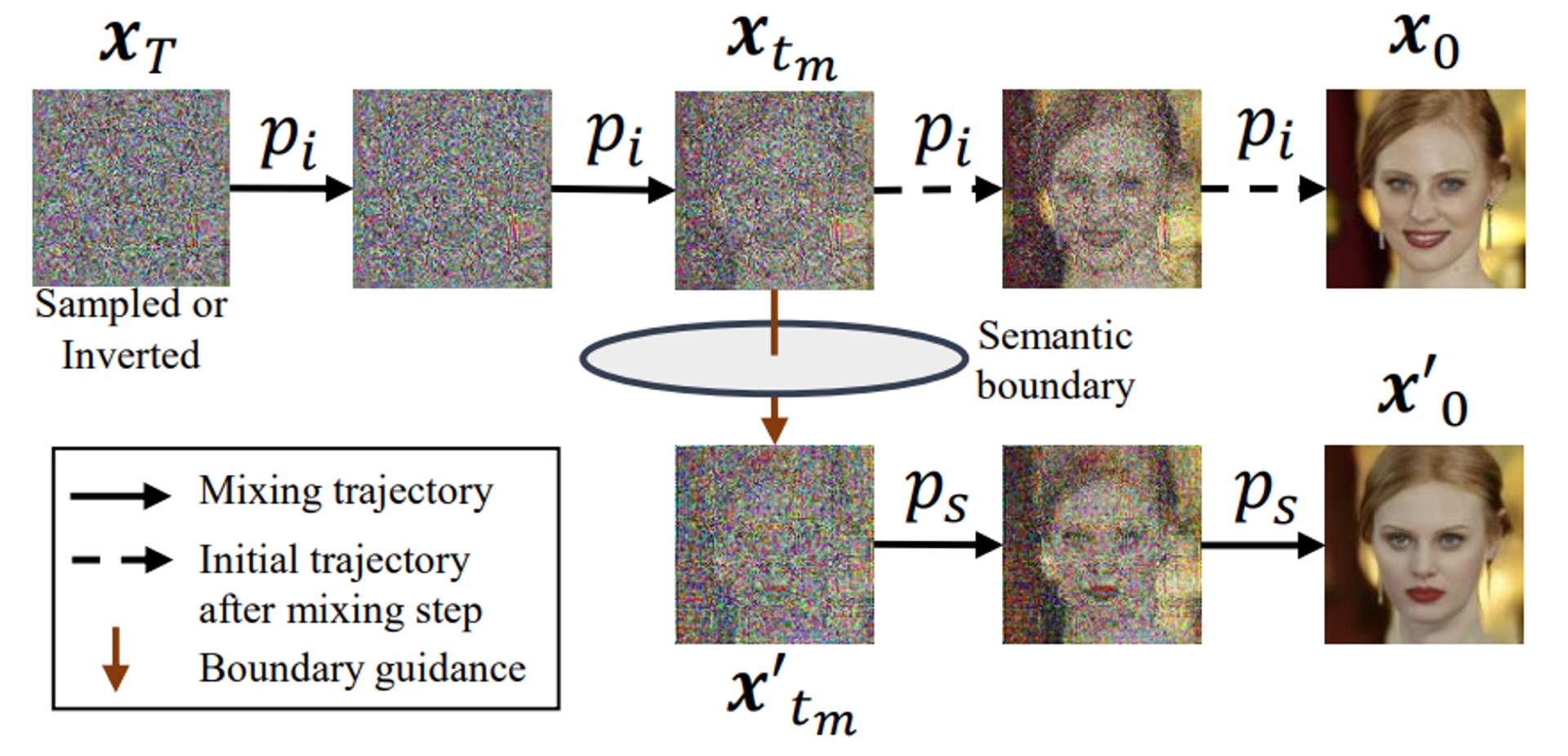
根据高维高斯分析,普通随机采样的x_T大概率处在一个球面赤道位置的小带子上,但是用ddim做inverted latent space,比x_T要小那么一圈,所以在小概率区域。那么神经网络自然对小概率区域,预测是不准的。
于是作者提出,那么可以不在x_T上进行语义操作。等反向过程中某个x_t,inverted latent space和普通随机采样的高概率区域差不多的时候,进行语义操作就好了。作者实验发现,等高斯分布半径差不多到4的时候,就是比较好的时机了。
#phd#PhD日常 #ai#AI #学习#学习 >>阅读更多

用户:Alexos
2023-08-18 12:44:35 晴
友友们,书接上回,有没有在美国的硕士或者博士能赏个脸解答下。#美国 #美国留学生 #Phd #生化环材 #海外博士
1. 美国有哪些学校药学专业比较好啊,我专业是药学,方向算是偏化学类和有机合成一点的,想了解下哪些,信息太闭塞了。
2. 现在美国收Phd的话要求GRE的学校多嘛,我现在TOEFL马上要考了,应该没问题。但是我现在马上研三了,GRE没时间和精力准备了,想知道如果没GRE成绩的话对申请学校的限制会很大嘛[捂脸哭] >>阅读更多
用户:@…@
2023-12-17 22:33:39 晴
有没有海外的博士,想咨询一下博士面试经验[哇][哇][哇]
#申请博士 #Phd #博士申请 >>阅读更多
用户:KIRIKO
2024-02-05 12:36:38 晴
Call me worker.
#工作日 #科研 #今天发paper了嘛 #PhD >>阅读更多


用户:只吃饭不吃亏
2023-09-13 14:28:34 晴
好好好今天的新知识是网易云音乐教的#PhD >>阅读更多

用户:梦想照进现实
2024-02-28 15:41:14 晴
博士期间,其实没学到啥[满脸问号][满脸问号][满脸问号]#PhD >>阅读更多

用户:nowhere
2023-11-18 18:24:05 晴
现在流行的多抗防御的方法都涉及classifier对于OOD样本的预测,使得模型表现难以控制。那么有什么办法去避免使用classifier在OOD样本上做预测呢?
这篇文章指出,扩散模型本身就可以用ELBO和贝叶斯定理对ID数据做分类。不仅如此,扩散模型还可以将OOD数据拉到ID。由此,扩散模型可以实现 classifier-free的对抗防御。#phd#PhD日常 #学习 >>阅读更多
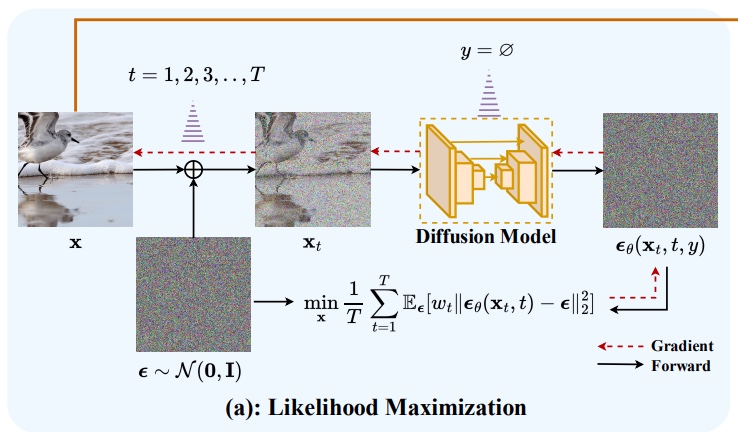

用户:kko
2023-11-15 10:04:26 晴
我还在想哪个艺高人胆大的敢去套乔姆斯得基的兹#PhD >>阅读更多

用户:憨厚的派大星
2024-04-17 21:30:31 晴
#你的朋友圈几天可见? 我选择:没设置。主打一个真实,也没什么不可见的的内容。 >>阅读更多




